인과추론 기법들 중에서도 DID(Difference-in-Differences)는 원리가 비교적 직관적이고 간단해서 실무에서 자주 사용되는 방법론이다. DID는 어떤 정책이나 처치가 실제로 효과가 있었는지 알아보기 위해, 단순히 전후 비교나 집단 간 비교만 하는 것이 아니라 ‘변화량의 차이’를 측정함으로써 보다 정확한 인과효과를 추정한다. 이번 글에서는 DID의 기본 개념과 작동 원리를 살펴보고, 이를 위해 어떤 가정이 필요한지 알아보자.
DID란?
차이의 차이(DID, Difference In Differences)
2번의 차분을 통해 Treatment effect를 추정하는 방식
그룹 내의 gap : Time series comparison
그룹 간의 gap : cross-sectional comparison
How-to
인과추론의 가장 기본적인 접근 방법은 A라는 행동의 성과를 만약 그 행동을 하지 않았더라면 발생했을 성과(counterfactual)와 비교하여 순수한 A 행동의 효과를 측정하는 것이고, 이에 따라 Counterfactual을 잘 선정하는 것이 가장 중요하다.
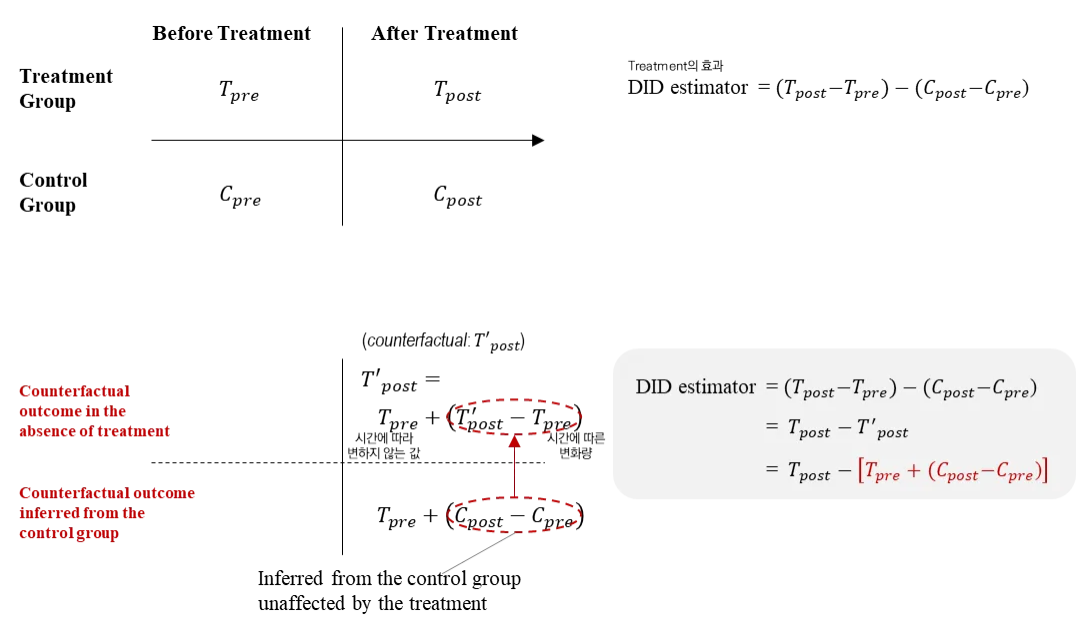
DID를 인과추론 관점에서 다시 보면, 측정이 불가능한 시간에 따른 변화량( $T’_{post}-T_{pre}$)을 control group의 시간에 따른 변화량($C_{post}-C_{pre}$)으로 치환하여 treatment effect를 측정할 수 있다(그림 1).
따라서 DID 분석의 신뢰도는 control group과 counterfactual의 유사성에 달려있다. 다만 counterfactual 전체가 아닌 시간에 따른 변화량만을 치환하므로 변화량에 대한 유사성만 증명하면 된다. 즉 counterfactual과 트렌드 정도만 같아도 충분하므로 control group을 선정하는 것이 상대적으로 용이하다.
그림 1. DID 추정 원리 (source: 인과추론의 데이터과학)
Identification strategy
Identification strategy는 관측 데이터로부터 우리가 관심있는 인과효과를 어떻게 신뢰 가능하게 분리해낼 것인가에 대한 논리적 설계 전략을 의미한다.
주로 counterfactual을 어떻게 만들어낼 것인지, 선택 편향을 어떻게 제거할 것인지, 기본적으로 어떤 가정이 필요한지 등의 문제를 해결하고자 한다.
Identification assumption
Parallel trend assumption
DID의 기본 가정으로, 두 그룹의 시간에 따른 변화 트렌드가 같아야 한다는 가정
Parallel trend는 시간의 변화량과 변화 패턴의 유사성만 충족하면 되므로 상대적으로 증명이 쉽다. 그래프를 통해 Treatment 이전/이후의 트렌드를 확인하는 방식이 일반적이다.
Staggered treatment 등 시각적으로 확인하기 어려운 경우 event study를 통해 간접적인 통계적 검정이 가능하다.
그러나 Parallel pre-trend assumption이 충족되었을지라도 Parallel post-trend가 보장되지는 않는다.
그림 2. Pre-period에 두 그룹 간 변화 트렌드가 동일함을 그래프로 확인할 수 있다 (source: 인과추론의 데이터과학)
Exogeneity of Treatment Assignment (Exchangeability)
Treatment가 독립변수와 독립적이어야 한다.
우연히 treatment가 적용되는 시점에 동시에 발생한 현상(contemporaneous trend) 또는 treatment와 상관성이 있는 confounder가 있다면(post-treatment confounder), post-trend 시점에 영향을 받을 수 있기 때문에 이러한 요인이 있는 지 반드시 점검해야 한다.
No spillover effect : 한 그룹에서의 인과효과가 다른 그룹에 영향을 주지 않아야 한다.
OLS 기본 가정
Pre-trend adjustment
Parallel pre-trend는 covariates 또는 fixed effect를 제어함으로써 보정할 수 있으나, 모두 제약이 있다.
Controlled covariates가 post period에 treatment의 영향을 받는 경우 post-treatment bias가 발생할 수 있다.
Fixed effect는 post-treatment bias를 일으키지는 않으나, 과거의 treatment가 현재의 outcome에 영향을 미치거나, 과거의 outcome이 현재의 treatment에 영향을 미치는 경우 또 다른 bias를 일으킬 수 있다.
따라서 DID 분석에서는 covariates를 통제하는 방식보다 매칭을 통해 Post-period bias를 제어하는 것을 선호한다.
매칭은 전체 기간이 아닌 Pre-period의 covariates만을 사용하므로 Post-period 시점에 treatment에 영향을 받을 일이 없으므로 선호된다.
또는 IPW나 Doubly robust DID를 사용할 수도 있다.
(참고) Abadie, 2005: “Semiparametric Difference-in-Differences Estimators.” Review of Economic Studies.
또는 log-transformation 등 functional form을 변환함으로써 Pre-trend parallel trend가 성립할 수도 있다.
이에 따라 binary outcome에 대한 DID 분석에서는 probit 또는 logit 모델보다는 OLS로 대표되는 Linear Probability Model(LPM)이 더 선호된다.