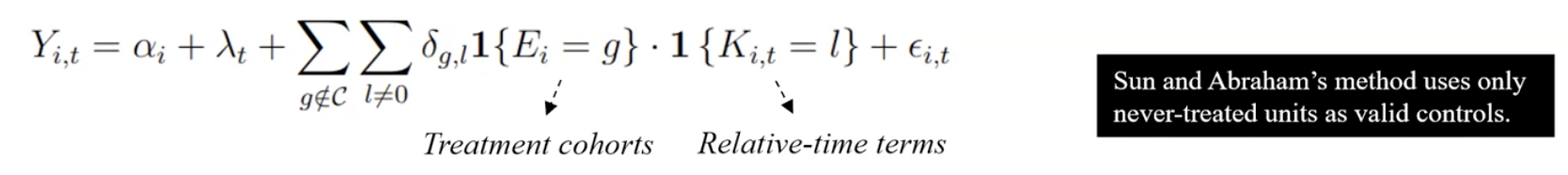앞에서 살펴 본 고전적인 DID(Canonical DID)는 treatment가 모든 유닛에 동일한 시점에 적용되었다는 것을 가정한다. 만약 유닛마다 서로 다른 시점에 treatment를 받는다면 어떻게 해야 할까? 현실적으로 treatment 적용 시점이 다른 경우가 많기 때문에 최근 들어 다양한 분야에서 Staggered DID의 활용 빈도가 높아지고 있다. 이번 글에서는 Staggered DID에 대해 이해하고 대표 방법론을 알아보겠다.
Staggered DID
Treatment 할당 시점이 유닛마다 다른, 즉 staggered treatment adoption(= multiple treatment timings)이 발생하는 경우 Staggered DID를 고려해야 한다.
Staggered DID는 한 번 처치를 받은 유닛은 그 상태를 계속 유지한다는 것을 가정한다. 즉 처치가 원복되는 reversible treatment 상황은 고려하지 않는다.
최근 들어 다양한 분야에서 staggered DID의 활용 빈도가 높은데 이는 현실적으로 treatment가 적용되는 시점이 다른 경우가 많고, parallel trend assumption을 만족하기 위해 반드시 배제되어야 할 contemporaneous trend 혹은 post-treatment confounder의 가능성을 더 낮출 수 있기 때문이다.
그러나 기존에 많이 활용하던 TWFE DID Model로 Staggered treatment 상황을 분석하는 경우 DID estimator가 가중 평균되는 오류가 있음이 최근 연구를 통해 밝혀졌다. 따라서 staggered treatment 상황에서는 TWFE를 수행함에 많은 주의를 기울여야 한다.
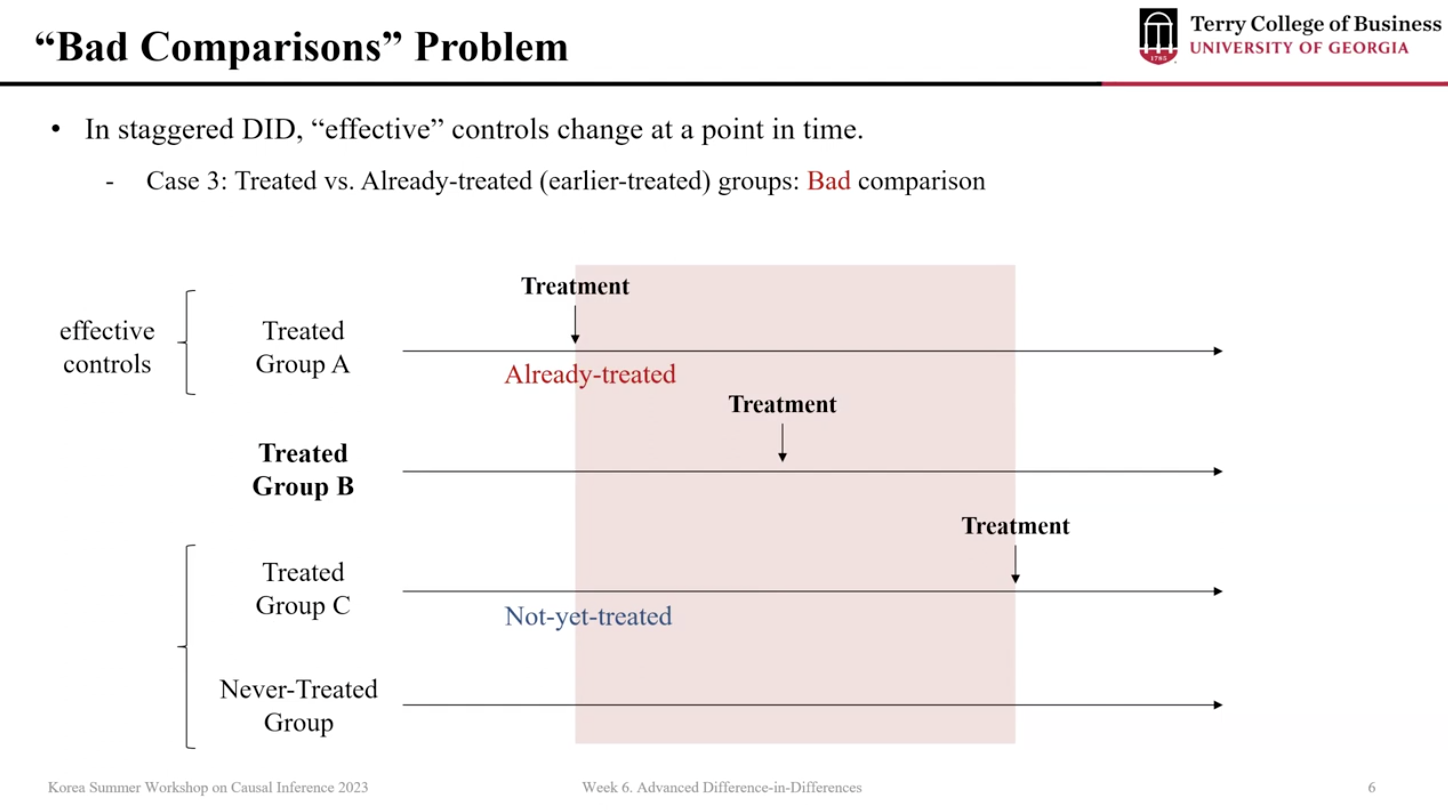
그림 1. Bad comparison problem (source: 인과추론의 데이터과학)
유닛은 세 개의 유형으로 나눌 수 있다.
never-treated units : 한 번도 처치를 받지 않은 유닛
not-yet-treated(later-treated) units : 아직 처치를 받지 않은 유닛
already-treated(earler-treated) units : 이미 처치를 받은 유닛
각 시점 t마다 treated unit i는 위의 3개 유형과 비교하게 되는데, 이 때 already-treated unit과 비교하는 경우 잘못된 비교를 수행하게 된다(bad comparison). 이미 처치를 받은 유닛을 counterfactual로 사용하게 되는 오류가 발생하는 것이다.
최악의 경우 bad comparison은 모든 ATT가 양수임에도 불구하고 음의 효과가 있다는 결과를 얻게 만들 수도 있고, treatment variance가 클수록 이와 같은 weight은 더 커진다.
treatment의 효과가 treatment cohort(treatment 적용 시점이 같은 그룹) 간 동일하고, 그 효과가 시간에 따라 변하지 않는다면(heterogeneous treatment effect) TWFE 추정치도 문제가 없다. 그러나 그렇지 않은 경우(dynamic treatment effect)라면 편향된 결과를 얻게 된다.
수식에서 $Treat_i*Post_{it}$는 treatment group에 대해서만 정의되므로 $Post_{it}$와 동일하다. 그러나 매칭 등을 통해 control group에 대해서도 $Post_{it}$를 정의할 수 있다면 동일하지 않을 수 있다.
1. Local DID Approach
valid comparison만 분리하여 local하게 ATT를 개별적으로 추정하고, 이를 결합하여 overall ATT를 추정하거나 event-study model처럼 dynamic treatment effect를 추정하는 방법론
Callaway and Sant’Anna (2021)
유닛별 최초 처치일을 기준으로 코호트(treatment cohort)을 나눈다. 예) time 1에 처치를 받은 유닛은 cohort 1, time 2에 처치를 받은 유닛은 cohort 2 등. 그룹별로 인과효과를 추정하기 때문에 고전적인 DID처럼 모든 유닛에 효과가 동일하다고 가정하거나, 공변량에 따라 효과가 선형으로만 달라진다는 가정이 더 이상 필요하지 않다. 즉, treatment heterogeneity로 인한 오류를 줄일 수 있다.
각 코호트에 대하여 연도별로 DID를 수행하되 never-treated 또는 not-yet-treated 까지만 포함하여 cohort x time별로 ATT를 추정한다.
Treatment(t) 이후 시점의 ATT 추정 시에는 처치시점의 t-1을 baseline으로 하되(여기서는 2009년), pre-treatment 시점에는 추정시점 t-1을 baseline으로 사용한다(2005년에 대한 pre-treatment ATT는 2004년을 baseline으로 사용)
Sun and Abraham (2021)
Sun and Abraham 방법론은 기존 TWFE event-study 모델에 코호트를 추가하고, auxiliary regression을 이용하여 그룹 별 여러 시점의 처치 효과를 가중 평균으로 표현하는 방식을 취한다. 이 방법은 그룹별 비중을 가중치로 추정하는 방식으로 직관적으로 각 그룹이 전체 평균 인과효과에 기여하는 정도를 해석할 수 있게 만든다.
여기서 auxiliary regression이란 코호트 x event-time interaction term을 먼저 추정하고, 이 계수를 코호트 비중을 사용해 재가중함을 의미한다.
Callaway and Sant’Anna 방법론과 다른 점은 TWFE event-study를 적절하게 수정하는데 초점을 맞추고, never-treated 또는 last-treated(가장 마지막에 처치를 받는 유닛)만 사용하며, baseline을 pre-treatment 기간에도 수행시점 t-1으로 설정하는 경향이 있다는 점이다.
Imai et al.(2023)
treatment unit에 대해서 동일한 treatment history를 공유하는 unit과 매칭하여 valid control group 구성한다.
분석 예시
Overall ATT는 개별 $ATT_t$ 와 $ATT_{t+1...n}$의 평균으로 산출한다.
$ATT_{t-1}$은 왜 구했을까? → DID의 기본 가정인 parallel trend assumption을 충족하려면 $ATT_{t-1}$가 0에 가까워야 한다(해당 예시는 pre-treatment parallel trend assumption을 위배하므로 DID 분석에 적절하지는 않다)
2. Imputation methods
never-treated group을 이용하여 counterfactual outcome을 예측하고 이를 기반으로 observed outcome과 비교하여 ATT를 추정하는 방법론