DID - 2. DID의 일반화 - TWFE 모델 (2)
Causal Inference ·지난 글에서는 TWFE 모델의 기본 개념과 unit fixed effects와 time fixed effects가 교란 요인을 어떻게 통제하는지 살펴봤다. 이번 글에서는 Fixed effects 모델을 추정하는 방식 중 LSDV와 Within Estimator의 원리를 이해하고 이를 TWFE로 확장해본다. 또한 샘플 데이터를 활용해 각 방식으로 인과효과를 추정하는 과정을 코드와 함께 구체적으로 살펴보자.
Estimation
Fixed Effects Model
$ Y_{it}=\beta_i+\beta_1X_{it}+\epsilon_{it} $
- 단순 fixed effects model은 unit을 통제하는 기법으로 유닛 간의 변동(between-variation)을 제어한다. fixed effects를 통해 시간에 따라 변하지 않는(time-invariant) unit의 특성을 통제한다.
- Fixed effects 모델은 unit 마다 개별 Intercept를 갖는다.
- 직관적으로 unit 마다 개별 특성을 제어한다는 의미로 이는 unit 마다 binary variable을 더해주는 것과 같은 역할을 한다. 각 $\beta_i$는 ith binary variable의 efficient이다.
- intercept가 분리됨으로써 unit 마다의 regression line이 분리된다.
- 개별 intercept로 regression line을 추정하는 방식은 2가지가 있다.
- LSDV (Least Squares Dummy Variables)
- unit의 특성을 이진 더미 변수로 처리하고 회귀분석을 진행하는 방식 (n개의 unit에 대해 n-1개의 더미변수 생성)
- 추정해야 하는 파라미터가 너무 많아서 과적합 또는 자유도 감소 문제가 발생할 수 있다. 따라서 unit 수가 적고 unit 간의 특성 차이가 중요한 경우에 사용한다.
- Within Estimator
- unit 에서 시간에 걸친 평균값을 먼저 계산하고 원래 모형에서 평균값을 빼준다.
- $Y_{it}-\bar{Y_i}=\beta_0+\beta_1(X_{it}-\bar{X_i})+\epsilon_{it}$
- X가 단위 1만큼 높을 때 y가 $\beta_1$만큼 높다고 해석할 수 있다.
- Fixed effects 모델의 $R^2$는 within $R^2$로, Y의 전체 변동성이 아닌 내부 변동성(within variation)에 비해 잔차가 얼마나 변동하는지를 측정한다. 고정효과 제거 후 시간에 따른 변동성을 얼마나 설명하는가?
- LSDV (Least Squares Dummy Variables)
Two-Way Fixed Effects model (TWFE)
\[Y_{it}=\beta_i+\beta_t+\beta_1X_{it}+\epsilon_{it}\]- TWFE 모델은 unit effects와 time effects를 모두 포함한다.
샘플 데이터로 살펴보기
샘플 데이터로 2가지 추정 방식을 수행하고 그 결과를 비교해보자. 데이터는 이전 글에서 사용했던 샘플을 일부 가공하였다.
| customer_id | day | push_notification | purchase_amt | dummy1 | dummy2 | dummy3 | dummy4 | time1 | time2 | time3 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 20251014 | 0 | 50 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 20251015 | 1 | 70 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 20251016 | 1 | 70 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 20251014 | 0 | 10 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 20251015 | 1 | 30 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 20251016 | 1 | 50 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 3 | 20251014 | 0 | 30 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 3 | 20251015 | 0 | 20 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 3 | 20251016 | 0 | 10 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 4 | 20251014 | 0 | 60 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 4 | 20251015 | 0 | 40 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 4 | 20251016 | 0 | 60 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
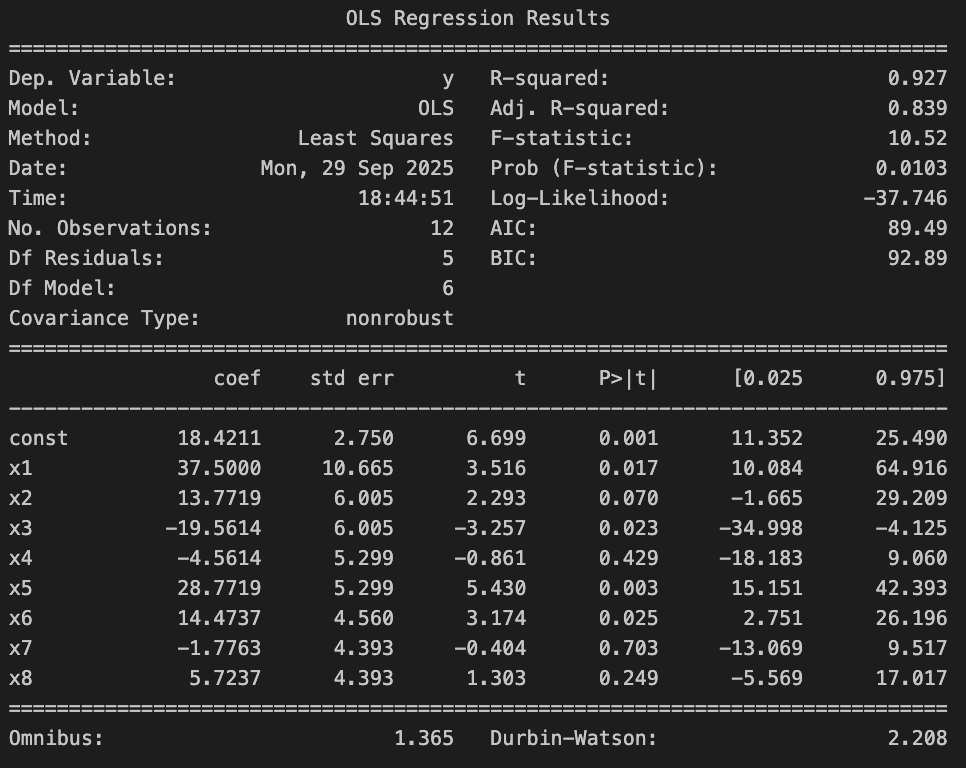
LSDV
- LSDV 방식은 unit 마다의 dummy variable(dummy1, 2, 3, 4)과 시점 마다의 dummy variable(time 1, 2, 3)을 생성한다.
- 회귀모델 결과를 보면 push_notification(x1)의 계수는 37.5. 즉 push 메세지 알림을 받은 경우 받지 않았을 때보다 평균 구매 수량이 37.5 증가한다고 해석할 수 있다.
import pandas as pd
import statsmodels.api as sm
import numpy as np
df = pd.read_csv('fixed_effects_exercise.csv')
# linear regression
col_x = ['push_notification', 'dummy1', 'dummy2', 'dummy3', 'time1', 'time2', 'time3']
col_y = 'purchase_amt'
X = df[col_x].to_numpy()
y = df[col_y].to_numpy()
X_const = sm.add_constant(X)
df_fit = sm.OLS(y, X_const).fit()
print(df_fit.summary())
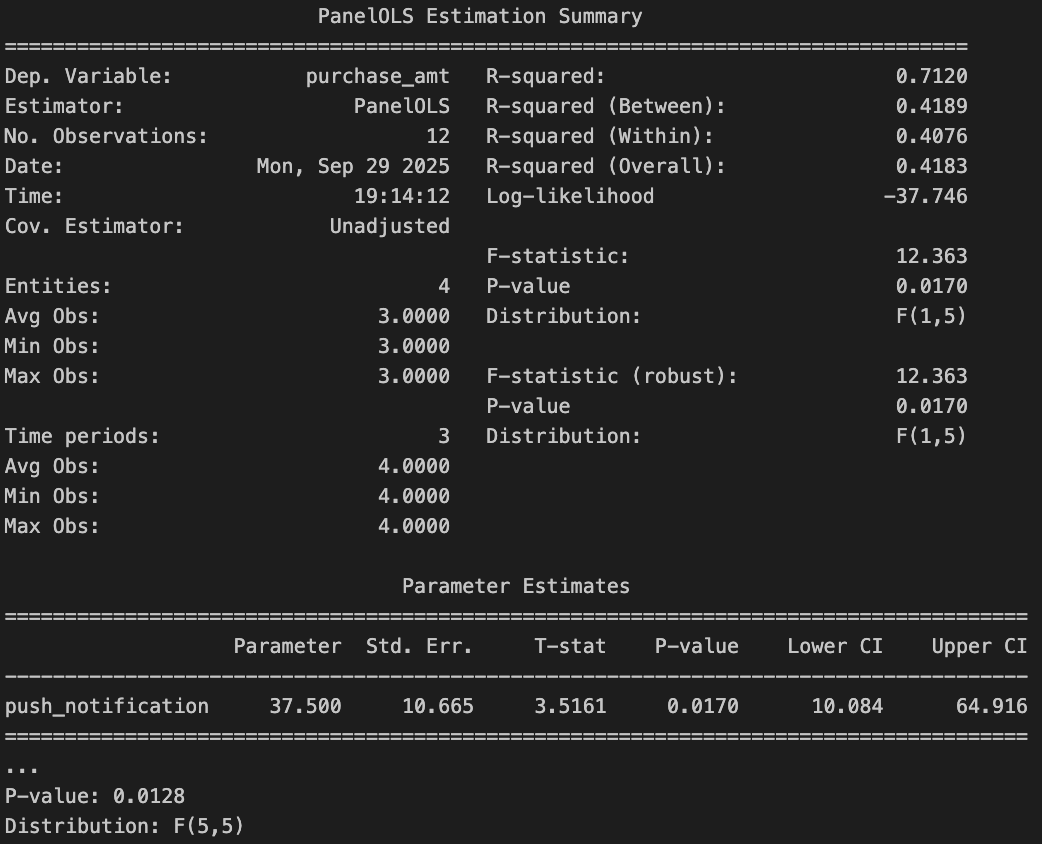
Within Estimator
- LSDV 방식은 직관적이지만 unit이 많을 때는 사용하기가 어렵다.
- 위와 동일하게 push_notification의 계수가 37.5로 추정되는 것을 볼 수 있다.
import linearmodels as lm
import pandas as pd
df = pd.read_csv('fixed_effects_exercise.csv')
df = df.set_index(['customer_id', 'day'])
mod = lm.PanelOLS.from_formula('''purchase_amt ~ push_notification + EntityEffects + TimeEffects''', df)
twfe = mod.fit()
print(twfe)