CUPED - 더 빠르게 실험 결과를 얻는 방법
Experiments ·실험을 하다보면 지표의 신뢰구간이 넓어 0을 포함할 때가 있다. 두 집단 간의 차이는 0과 꽤 떨어져 있는데 넓은 신뢰구간이 0을 포함하면 지표를 해석하는 것이 상당히 난감해진다. 지표의 분산을 줄이려면 어떻게 해야 할까? 가장 간단한 방법은 표본 크기를 늘리는 것이다. 전체 트래픽의 일부를 사용한 실험이라면 트래픽 비중을 최대 50%까지 높일 수 있다. 실험 기간을 연장하여 표본 크기를 늘리는 방법도 있다. 다만 실험 기간을 늘리는 것은 유저의 장기적인 행태에도 영향을 받을 수 있어 분산이 줄어들지 않을 가능성도 있다.
2013년 MS는 분산을 줄이기 위한 또다른 방법을 제안했는데 이것이 CUPED, Controlled experiment Using Pre-Experiment Data 이다. CUPED의 컨셉은 표준적인 delta 보다 분산이 더 작고, 더 효율적인 ATE 추정량을 사용하는 것이다.
먼저 통제변수 기법을 이해하고, CUPED가 통제변수 기법의 제약점을 어떻게 해소했는지 살펴본 후 실제 데이터에 적용하는 방식을 정리해보겠다. 이 글은 레퍼런스를 기반으로 세부 설명을 덧붙여 작성했고, CUPED의 근간이 되는 논문도 함께 읽어보는 것을 추천한다.
Control Variate
- 반복된 무작위 추출을 이용하여 수학적, 통계적 문제의 해를 근사적으로 구하는 몬테카를로 시뮬레이션도 두 집단의 차이인 delta를 추정하기 때문에 여기서도 분산을 줄이는 것이 관건이다.
- Control variates(통제변수) 기법은 더 작은 분산을 갖는 대안적 몬테카를로 추정량을 제공한다. 이 때, 통제변수로 사용할, 기댓값 $\mu_x = \mathrm{E}(X)$을 알고 있는 확률변수 X가 필요하다.
- 통제변수가 어떻게 기댓값을 유지하면서도 분산을 줄여줄까? 먼저 임의의 $\theta$에 대해, 다음의 추정량 또한 $\mathrm{E}(Y)$의 불편추정량이 된다. 즉, 원래의 지표에 통제변수를 추가해도 기댓값은 변하지 않는다.
$$ \hat{Y}_{cv}:=\bar{Y}-\theta\bar{X}+\theta \mu_x $$ - 평균이 0인 것을 빼거나 더해도 기댓값은 변하지 않는다는 성질을 이용한다.
- $X$라는 확률변수가 있고, $\mu_x = \mathrm{E}(X)$을 알고 있다면, $\mathrm{E}(X-\mu_x)=0$이다.
$$\mathrm{E}(X-\mu_x)=\mathrm{E}(X)-\mu_x=\mu_x-\mu_x=0$$ - 새로운 변수를 $Y_{cv}:=Y-\theta(X-\mu_x)$ 로 정의할 때, $Y_{cv}$의 기댓값은 다음과 같다.
$$ \mathrm{E}(Y_{cv})=\mathrm{E}(Y-\theta(X-\mu_x))=\mathrm{E}(Y)-\theta\mathrm{E}(X-\mu_x)=\mathrm{E}(Y) $$ - $\theta$값에 관계없이 $Y_{cv}$는 항상 $\mathrm{E}(Y)$와 같은 기댓값을 갖는다.
- 새로운 변수에 대해 분산 $Var(\hat{Y}_{cv})$은 다음과 같이 정의된다.
$$ \begin{aligned} Var(\hat{Y}_{cv}) &= Var(\bar{Y}-\theta\bar{X})\\ &= \frac{Var(Y-\theta X)}{n}\\ &= \frac{1}{n}(Var(Y)+\theta^2 Var(X)-2\theta Cov(Y,X)) \end{aligned} $$ - 이 분산은 $\theta=Cov(Y,X)/Var(X)$일 때 최소가 된다.
- 이 최적의 $\theta$를 대입하면,
$$ Var(\hat{Y}_{cv})=\frac{1}{n}(Var(Y)-\frac{Cov(Y,X)^2}{Var(X)}) $$ - 이 때 상관계수 $\rho=\frac{Cov(Y,X)}{\sqrt{Var(Y)Var(X)}}$를 대입하면,
$$ \begin{aligned} Var(\hat{Y}_{cv})&=\frac{1}{n}(Var(Y)-Var(Y)\rho^2)\\ &=\frac{1}{n}(Var(Y)(1-\rho^2)\\ &=Var(\bar{Y})(1-\rho^2) \end{aligned} $$ - 즉, 새로 정의한 $\hat{Y}_{cv}$는 기댓값이 동일하면서도 분산이 $\rho^2$만큼 감소하게 된다. $\rho$가 커질수록, X와 Y의 상관성이 높을수록 분산 감소 효과는 커진다.
$$ \frac{Var(\hat{Y}_{cv})}{Var(\bar{Y})}=1-\rho^2 $$ - 단일 control variate 케이스를 여러 변수를 포함하는 형태로 쉽게 일반화 할 수 있다. 선형회귀와 연결하여 생각해보면, 최적의 $\theta$는 결국 OLS 회귀에서 중심화된 Y를 중심화된 X에 회귀시켰을 때의 해와 동일하며, 여러 개의 변수를 사용하는 다변량 회귀에서도 해당 추정량의 분산은 다음과 같이 된다.
$$ Var(\hat{Y}_{cv})=Var(\bar{Y})(1-R^2) $$
CUPED
- 그러나 실무에서는 Y와 상관성이 높으면서도 $\mu_x$를 알고 있는 X를 찾는 것이 쉽지 않다.
- Alex Deng은 2013년 논문에서 랜덤화된 실험에서는 Control variate X의 $\mu_x$를 모르면 각 변형군의 평균은 구할 수 없지만 ATE는 구할 수 있음을 관찰했다.
- $\Delta^*$을 변형된 $Y_{cv}$값으로 정의하면,
$$ \begin{aligned} \Delta^{*} &:= \bar{Y}_{cv}(t) - \bar{Y}_{cv}(c)\\ &= \bar{Y}^{(t)}-\theta\bar{X}^{(t)}+\theta\mathrm{E}(X^{(t)})-(\bar{Y}^{(c)}-\theta\bar{X}^{(c)}+\theta\mathrm{E}(X^{(c)}))\\ &= \bar{Y}^{(t)}-\bar{Y}^{(c)}-\theta(\bar{X}^{(t)}-\bar{X}^{(c)})+\theta(\mathrm{E}(X^{(t)})-\mathrm{E}(X^{(c)}))\\ &= \Delta(Y)-\theta\Delta(X)+\theta(\mathrm{E}(X^t)-\mathrm{E}(X^c)) \end{aligned} $$ - 따라서 $\mathrm{E}(X^t)=\mathrm{E}(X^c)$를 만족하는, 즉 처치가 X에 영향을 주지 않는 X를 찾으면 되는데, 랜덤화된 실험에서는 pre-experiment 지표들이 이에 해당한다. 여기서 CUPED의 이름이 유래되었다.
- 정확히는 처치 개입이 trigger 되기 전의 지표를 의미한다. 반드시 Pre-experiment 지표가 아니더라도 처치와 무관한 지표(유저가 실험에 최초 개입된 요일, 연령, 성별, 브라우저/디바이스 정보 등)면 이에 해당한다.
- Alex Deng은 논문에서 CUPED를 적용했을 때 얼마나 분산이 감소하는지 보여준다.
- p-value는 $T=\frac{difference\;in\;means}{standard\;errors}$ 통계량에 의해 결정된다. 즉, 델타의 분산에 직접적으로 영향을 받는다. 따라서 위의 그래프에서 p-value가 절반 정도 줄어드는 양상을 통해 CUPED가 분산 감소에 기여함을 확인할 수 있다.
- 아래 그래프에서도 절반 크기의 샘플을 사용하더라도 CUPED가 전체 샘플을 사용한 t-test보다 더 작은 분산으로 p-value를 만들어냄을 확인할 수 있다.
- 최적의 $\theta=\frac{Cov(Y,X)}{Var(X)}$를 얻을 때, treatment group와 control group 중 어떤 값을 사용해야 할까? 처치 효과가 아주 큰 경우가 아니라면 일반적으로 그룹별 최적의 $\theta$ 값이 거의 비슷하기 때문에 어떤 값을 사용해도 무방하다. 그럼에도 불구하고 최적의 $\theta$를 찾고 싶다면 아래의 수식을 활용하거나 pooled data(변형군 구분없이 전체 데이터)를 활용할 수 있다.
$$ \frac{Cov(\bar{Y^t}, \bar{X^t})+Cov(\bar{Y^c}, \bar{X^c})}{Var(\bar{X^t}+\bar{X^c})} $$ - Pre-experiment 지표를 X로 취하는 경우, 실험 기간에 최초로 유입되는 유저는 지표 값이 존재하지 않는다. Alex Deng은 이런 경우 지표를 0으로 처리하되, pre-experiment에 유효한 값을 가지는지에 대한 여부를 binary indicator로 추가하는 방식을 권한다.
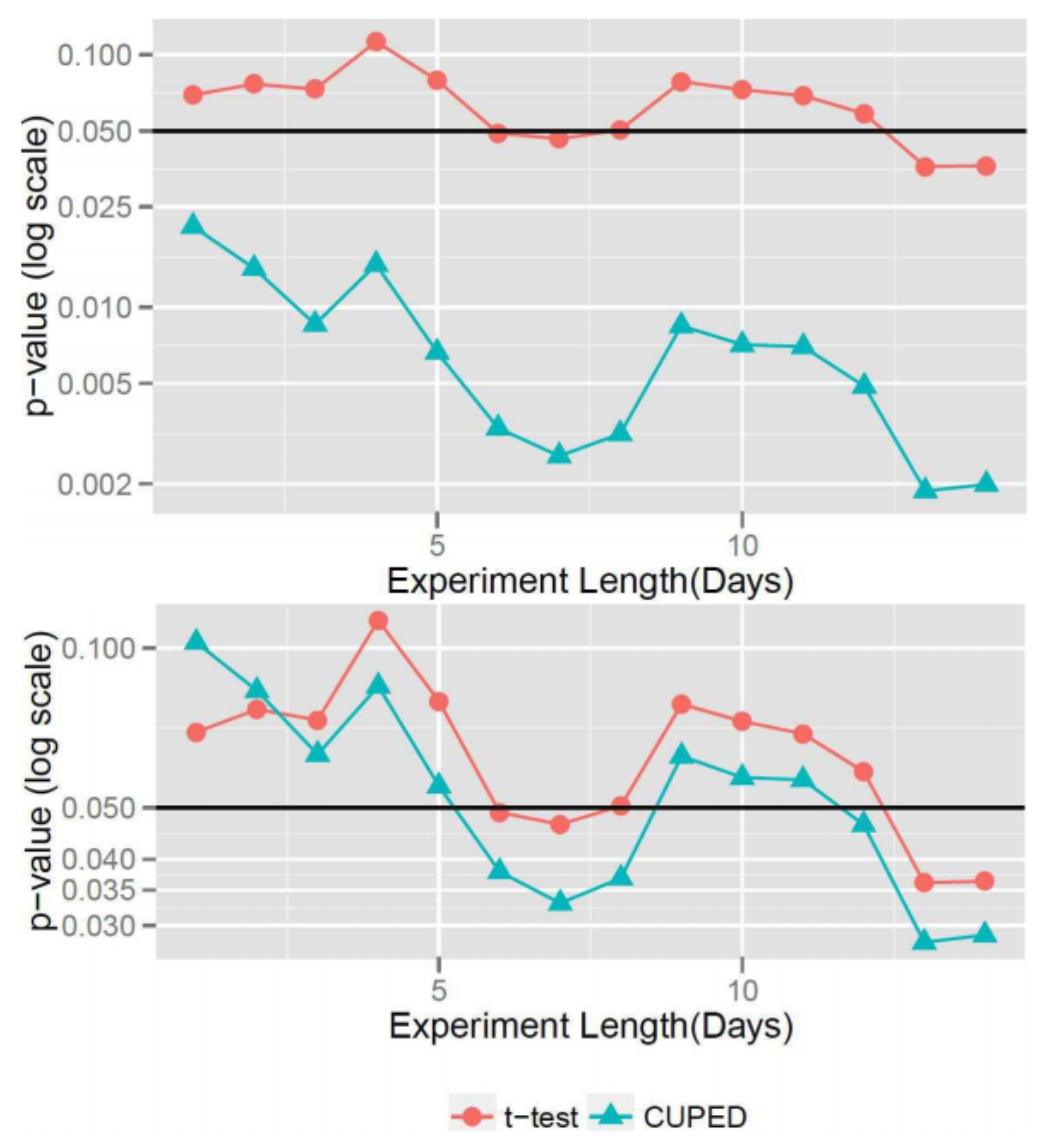
Top : p-value, Bottom : p-value when using only half the users for CUPED
CUPED 적용해보기
- Cov(Y,X)와 X의 평균, 분산을 연산하고, 이를 활용하여 최적의 $\theta$를 구한다.
- 각 사용자 별로 실험 이전 기간의 X 데이터를 계산한다.
- 전체 집단(population)의 통계값을 유저 레벨 데이터에 붙힌다.
- 유저별 변형된 지표를 생성한다. $Y_{cv}=Y-\theta X+\theta\mathrm{E}(X)$
- 변형된 지표로 기존의 통계 분석을 수행한다.