급격한 변화 포인트를 찾아주는 Piecewise Linear Regression
Stats ·최근에 광고 성과 분석을 하던 중 “광고비를 얼마나 써야 좋은 성과가 날까요?”라는 질문을 받았다. ROAS를 높이는 요인은 광고비 외에도 클릭수, 구매전환율, 객단가 등 다양하기 때문에 인과적인 효과는 사실상 단순한 분석으로는 파악하기 어렵다(높은 ROAS가 반드시 좋은 광고 성과를 의미하는 것이 아니기도 하다). 하지만 광고비를 어느 정도 썼을 때 전환금액의 증가율이 늘어나는지 패턴을 보면 최소한 광고비를 얼마나 세팅해야 할 지 가이드를 얻을 수 있다.
Piecewise Regression
데이터의 패턴이 급격하게 변화하는 포인트를 찾기 위해서 Piecewise Linear Regression을 사용해보았다. Piecewise Regression은 회귀 분석에서 독립 변수를 여러 구간으로 나누고, 각 구간마다 별도의 모델을 적합하는 기법이다. Segmented regression 또는 broken-stick regression 이라고도 한다.
일반적인 선형 회귀는 모든 데이터 범위에서 동일한 선형 관계를 가정하지만 현실의 데이터는 그렇지 않은 경우가 많다. 이런 데이터에서는 하나의 회귀식으로 모든 데이터를 설명하기 어렵고, 독립 변수가 서로 다른 구간에서 변수들 간의 관계가 다르게 나타날 때 Piecewise Regression이 매우 유용하다.
물론 비선형 효과를 고려하는 다항 회귀(polynomial regression), 회귀 스플라인(regression splines), 비모수 평활(non-parametric smoothing) 등의 다양한 방법들이 있다. 전통적인 방법론 대비 Piecewise regression은 2가지 장점을 갖는다.
- 데이터의 구간을 나누는 경계를 breakpoint 또는 knot value라고 하는데, 이 breakpoint를 사전에 고정하지 않아도 된다.
- 각 구간마다 별도의 모델을 만들기 때문에 각 구간마다 계수를 해석할 수 있다.
Piecewise Regression은 다앙한 분야에서 유용하게 쓰인다. 질병관리청은 Piecewise Regression을 활용해 기온별 온열질환자 발생의 정도가 달라지는 지점을 찾아 구간별 기온의 영향을 분석한 보고서를 발행했다.
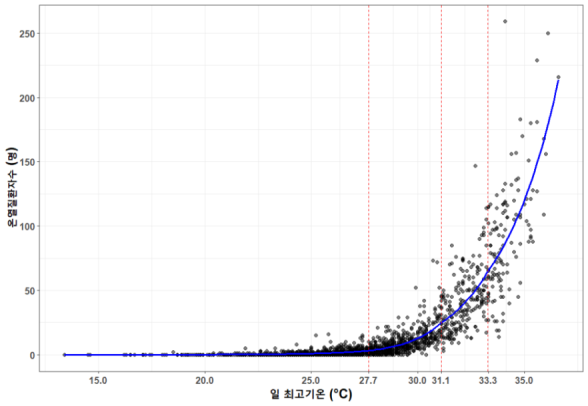
기온이 1℃ 오를 때마다 온열질환자는 일 최고기온 27.7℃~31.0℃ 구간에서는 약 7.4명, 31.1℃~33.2℃ 구간에서는 약 22명 증가했고, 특히 일 최고기온 33.3℃ 이상 구간에서는 기온이 1℃ 오를 때마다 온열질환자가 약 51명 발생하는 등 증가세가 급격한 것으로 나타났다. 이 결과를 바탕으로 질병관리청에서는 기상청에서 8월 말 낮 기온을 30~34℃로 전망하고 있기 때문에 온열질환 예방에 선제적으로 대응해야 한다는 메세지를 전했다.
Basis function
Basis function(기저함수)은 어떤 복잡한 함수를 표현하기 위해 기본 단위로 사용하는 함수들을 의미한다. 즉, 여러 개의 Basis function을 선형 결합하여 원래의 함수를 근사하거나 표현할 수 있다. Piecewise Linear Regression도 basis function의 결합으로 표현할 수 있다. 수학적으로는 다음과 같이 표현된다.
\[f(x)\approx\sum^{k}_{i=1}\beta_i\phi_i(x)\]- $\phi_i(x)$: i th basis function
- $\beta_i$: i th 계수 또는 가중치
- $k$: basis function 갯수
Piecewise Linear Regression에서는 입력 공간을 여러 구간으로 나누고 각 구간 내에서 서로 다른 선형 함수를 적합시키는데, 이 선형 함수들을 만들기 위해 다음 3개의 basis function을 정의한다.
- $h_1(x)=1\;(constant)$
- $h_2(x)=x$
- $h_3(x)=(x-k)_+ =max(0,\;x-k)$
이 중 $h_3(x)$가 Piecewise Linear Function의 핵심이다. 이 함수는 hinge function으로 x < k 이면 0, x ≥ k면 x-k 값을 가진다. 이를 통해 특정 지점 k에서 기울기가 변하는 효과를 만들어낸다.
Piecewise Linear Regression
데이터가 K개의 breakpoints $\tau_1, \tau_2,…,\tau_K$ 에 의해 K+1 구간으로 나뉜다고 할 때,
\[y=\beta_0+\beta_1x+\beta_2(x-\tau_1)_++\beta_3(x-\tau_2)_+...+\beta_{K+1}(x-\tau_K)_++\epsilon\]각 breakpoint부터 기울기가 추가로 변하면서 전체 구간을 여러 개의 직선 조각(piecewise linear)으로 나누어 모델링한다.
본 분석에서 사용한 piecewise-regression 패키지는 Muggeo의 2003년 논문 “Estimating regression models with unknown break-points”를 바탕으로 구현되었다. 이 패키지에서 사용하는 수식은 다음과 같다.
\[y=c+\alpha x+\beta(x-\psi)H(x-\psi)+\zeta\]- c : intercept
- $\alpha$ : $\tau_1$ 구간 회귀선의 기울기
- $\beta$ : $\tau_i, \tau_{i+1}$간의 기울기 변화량
- $\psi$ : breakpoint 위치
- $H$ : Heaviside step function
- $\zeta$ : noise term
이 때 임의의 시작점을 기준으로 Taylor expansion을 수행하여 선형 근사(linear approximation)함으로써 breakpoint estimate을 찾는다. 이는 본질적으로 비선형 최적화 문제인 breakpoint 추정을 선형 문제로 근사하여 효율적으로 해결하는 방식이다.
Modeling
import numpy as np
import matplotlib.pyplot as plt
import piecewise_regression
n_breakpoints = 2
def cutoff_upper_lower(series, upper_quantile=0.99, lower_quantile=0.01):
upper = series.quantile(upper_quantile)
lower = series.quantile(lower_quantile)
return series.where(series > lower, -0.9999).where(series < upper, -0.9999)
# 1. outlier 상하단 제거
pre_winsorize_columns = ['revenue', 'cost']
cutoff = 0.99
for col in pre_winsorize_columns:
df[col] = cutoff_upper_lower(df[col], upper_quantile=cutoff, lower_quantile=(1-cutoff))
for col in pre_winsorize_columns:
df_pwr = df[df[col] != -0.9999]
# 2. Log trasformation
transform_lst = ['revenue', 'cost']
df_pwr_log = df_pwr.apply(lambda x: np.log1p(x) if x.name in transform_lst else x)
pw_fit = piecewise_regression.Fit(df_pwr_log.cost.to_numpy(), df_pwr_log.revenue.to_numpy(), n_breakpoints=n_breakpoints)
pw_fit.summary()
# 3. Plot the data, fit, breakpoints and confidence intervals
pw_fit.plot_data(color="grey", s=20)
pw_fit.plot_fit(color="orange", linewidth=4)
pw_fit.plot_breakpoints()
pw_fit.plot_breakpoint_confidence_intervals()
plt.xlabel("Ad Cost")
plt.ylabel("Ad Revenue")
plt.show()
plt.close()
먼저 outlier를 상하단 1%씩 제거해주었고, 광고비와 전환금액 모두 right-skewed 되어 있기 때문에 log를 씌워주었다.
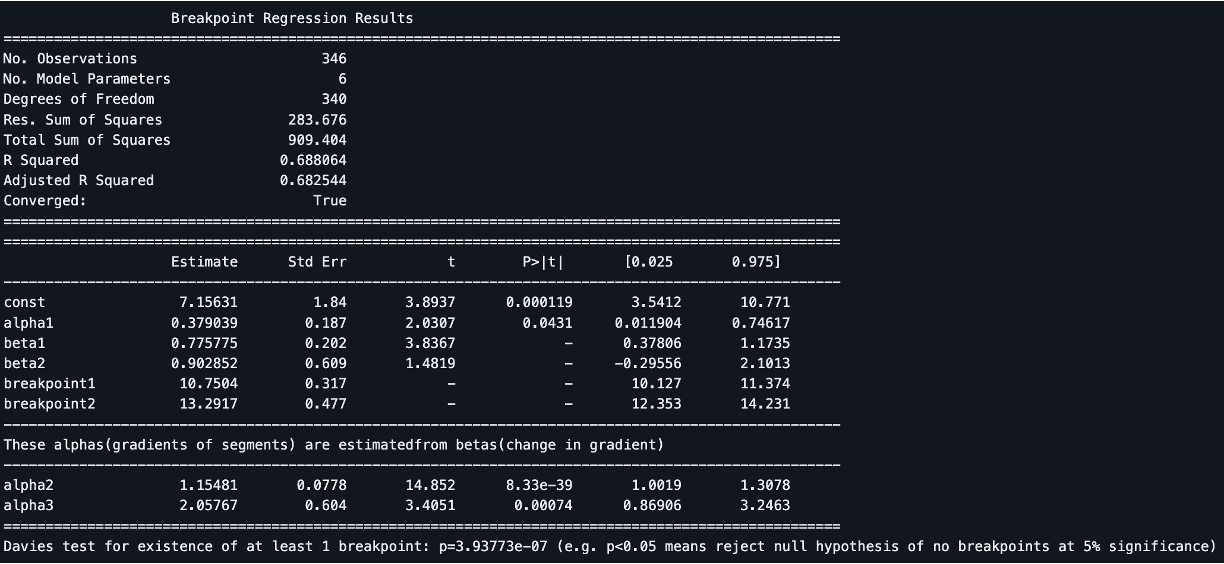
breakpoint를 2개로 설정했을 때 결과를 살펴보면 alpha1, alpha2, alpha3의 추정량은 구간별 선형 모델의 기울기를 의미한다. beta1, beta2는 각각 구간 1 → 구간 2 모델 간 기울기의 변화량, 구간 2 → 구간 3 모델 간 기울기의 변화량으로 alpha2 = alpha1 + beta1, alpha3 = alpha2 + beta2로 계산된다. breakpoint1, breakpoint2는 구간을 나누는 2개의 지점에 대한 추정량이다.
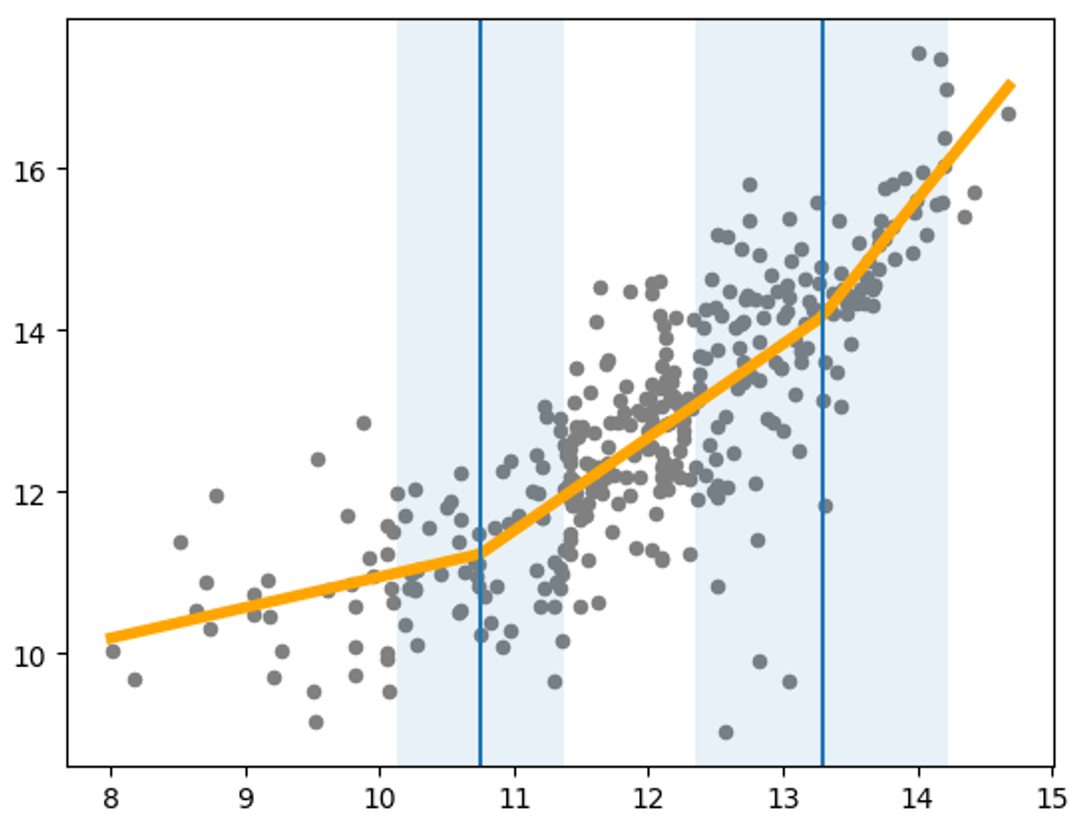
Piecewise Linear Regression을 시각화해보면 각 breakpoint에서 기울기가 변하는 모습을 볼 수 있다. 이 결과를 바탕으로 최소한 exp(10.7) 이상의 광고비를 들여야 어느 정도의 광고 효과가 있고, exp(13.3) 이상을 설정했을 때 좀 더 분명한 성과가 있을 것이라고 기대할 수 있다.
Reference
- https://www.medworld.co.kr/news/articleView.html?idxno=249656
- Muggeo, V. M. (2003). Estimating regression models with unknown break-points. Statistics
in Medicine, 22(19), 3055–3071